【前面的话】前面我们已经安装好了Elasticsearch,现在我们就来尝试简单的使用。
壹、Elasticsearch介绍

Elasticsearch是整个Elastic Stack的核心。
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
通过 Elasticsearch,您能够执行及合并多种类型的搜索(结构化数据、非结构化数据、地理位置、指标),搜索方式随心而变。先从一个简单的问题出发,试试看能够从中发现些什么。找到与查询最匹配的 10 个文档是一回事。但如果面对的是十亿行日志,又该如何解读呢?Elasticsearch 聚合让您能够从大处着眼,探索数据的趋势和模式。
贰、插件安装
由于ES官方并没有为ES提供界面管理工具,仅仅是提供了后台的服务。elasticsearch-head是一个为ES开发的一个页面客户端工具,其源码托管于GitHub,地址为:
https://github.com/mobz/elasticsearch-head。
安装方法也比较多:
1.源码安装,通过npm run start启动
2.通过docker安装
3.通过chrome插件安装
4.通过ES的plugin方式安装
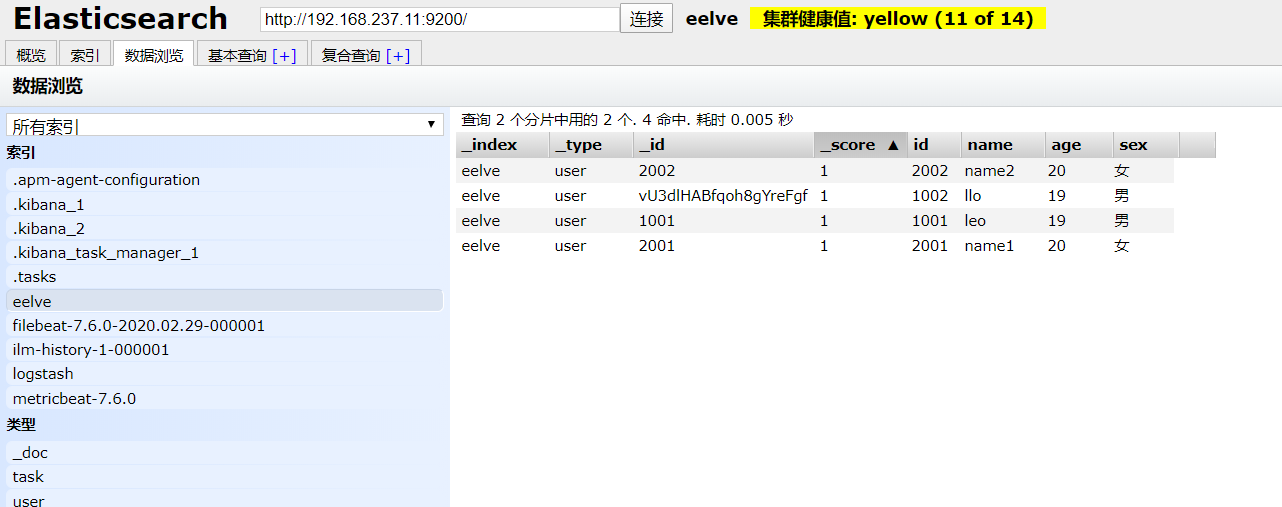
我这边就通过chrome插件的方式安装,在应用商店中搜索,然后安装即可,安装成功之后打开你会得到下面的页面
然后连接集群,就可以进行操作了
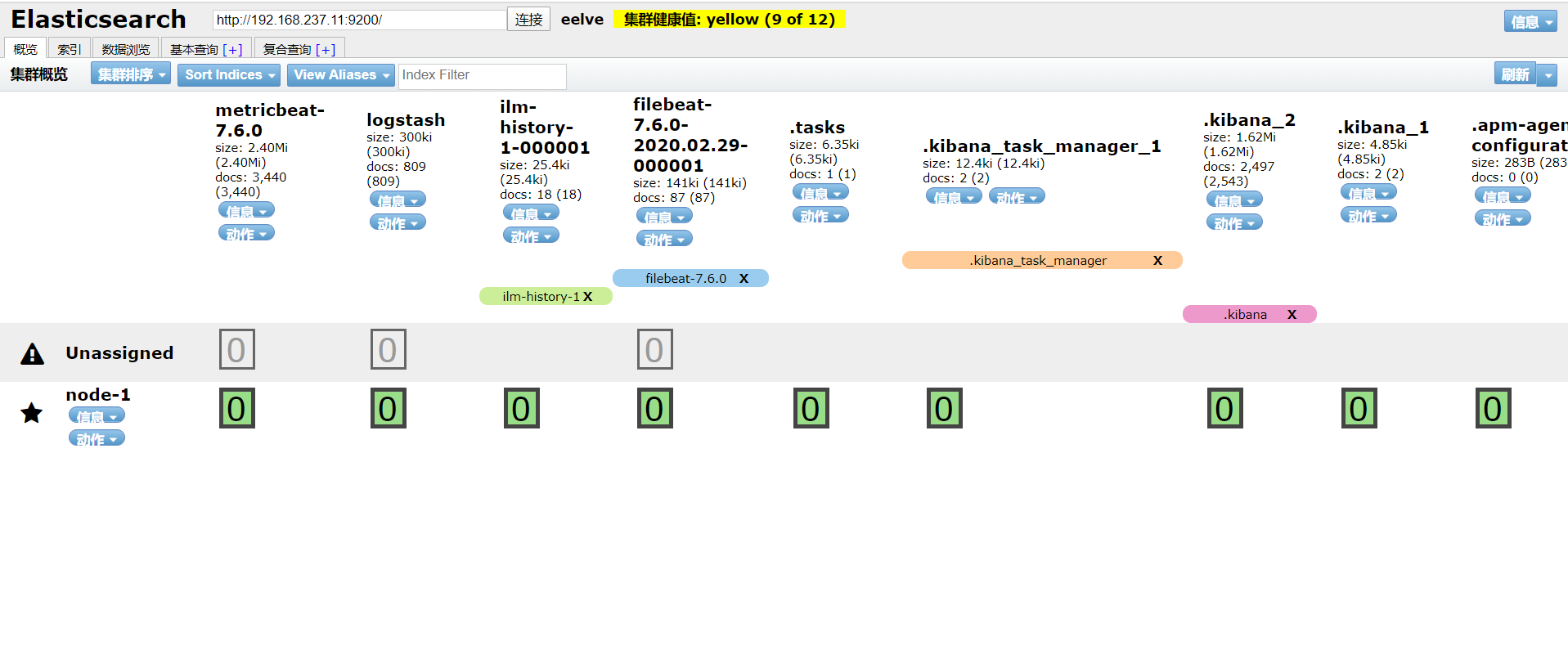
集群健康值
1.绿色:代表集群所有分片和副本都可用
2.黄色:代表集群中不是所有副本都可用,但是分片都可以用
3.红色: 代表集群中不是所有分片都可用
另外我的集群中出现了Unassigned,是因为我搭建的是单机版,而Elasticsearch默认会创建1个副本。
叁、简单使用
3.1 基本概念
索引
索引(index)是Elasticsearch对逻辑数据的逻辑存储,所以它可以分为更小的部分。
可以把索引看成关系型数据库的表,索引的结构是为快速有效的全文索引准备的,特别是它不存储原始值。
Elasticsearch可以把索引存放在一台机器或者分散在多台服务器上,每个索引有一或多个分片(shard),每个
分片可以有多个副本(replica)。
文档
存储在Elasticsearch中的主要实体叫文档(document)。用关系型数据库来类比的话,一个文档相当于数据库
表中的一行记录。
Elasticsearch和MongoDB中的文档类似,都可以有不同的结构,但Elasticsearch的文档中,相同字段必须有相
同类型。
文档由多个字段组成,每个字段可能多次出现在一个文档里,这样的字段叫多值字段(multivalued)。
每个字段的类型,可以是文本、数值、日期等。字段类型也可以是复杂类型,一个字段包含其他子文档或者数
组。
映射
所有文档写进索引之前都会先进行分析,如何将输入的文本分割为词条、哪些词条又会被过滤,这种行为叫做
映射(mapping)。一般由用户自己定义规则。
文档类型
在Elasticsearch中,一个索引对象可以存储很多不同用途的对象。例如,一个博客应用程序可以保存文章和评
论。
每个文档可以有不同的结构。
不同的文档类型不能为相同的属性设置不同的类型。例如,在同一索引中的所有文档类型中,一个叫title的字段
必须具有相同的类型。
3.2 RESTful API
在Elasticsearch中,提供了功能丰富的RESTful API的操作,包括基本的CRUD、创建索引、删除索引等操作。
下面我就通过Postman来演示一遍
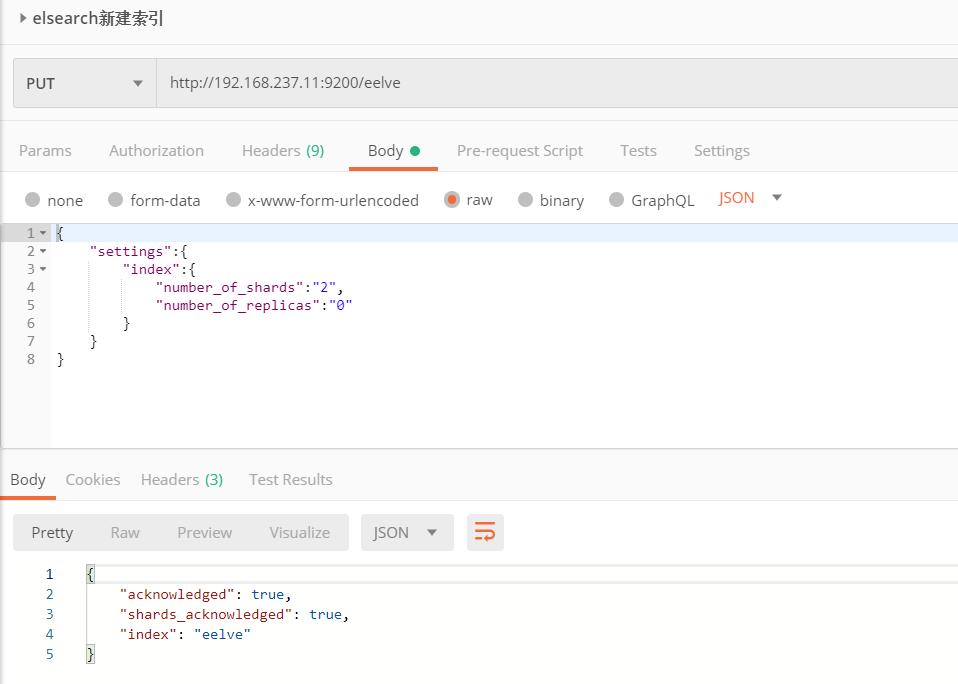
3.2.1 创建非结构化索引
1 | #创建索引 |
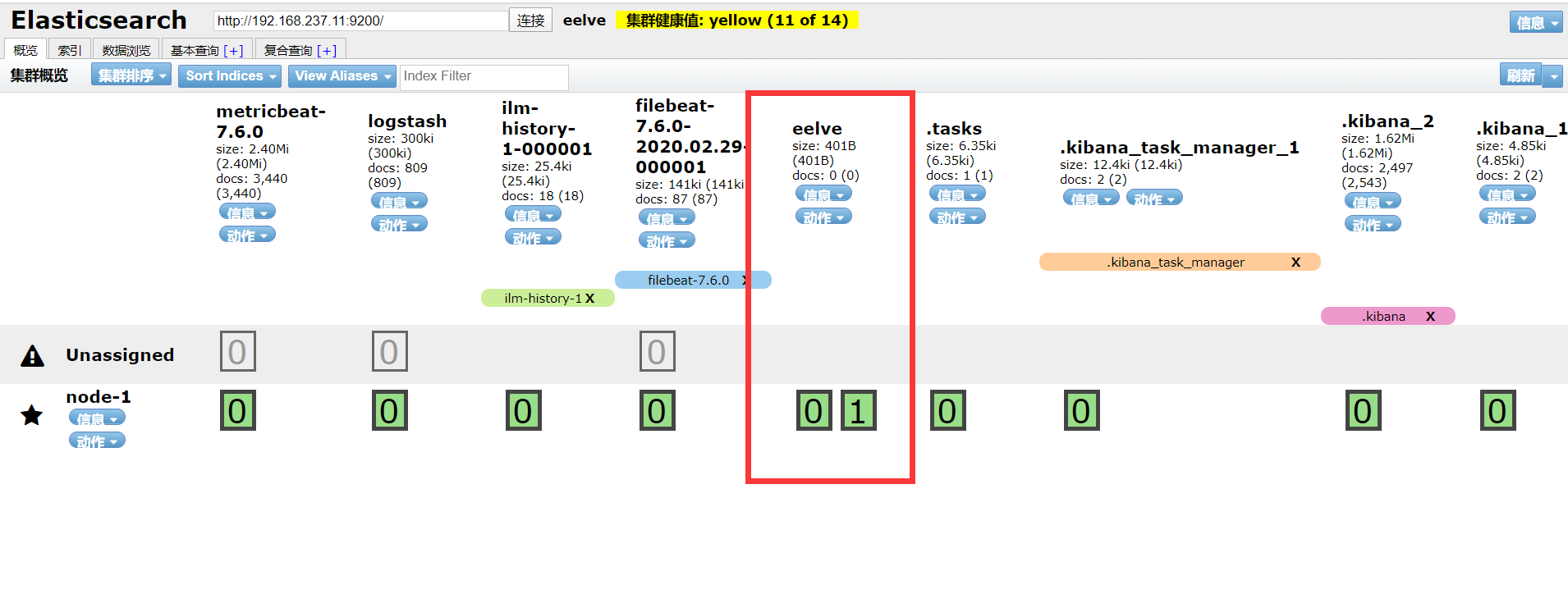
1 | #删除索引 |
3.2.2 插入数据
URL规则:
POST /{索引}/{类型}/{id}
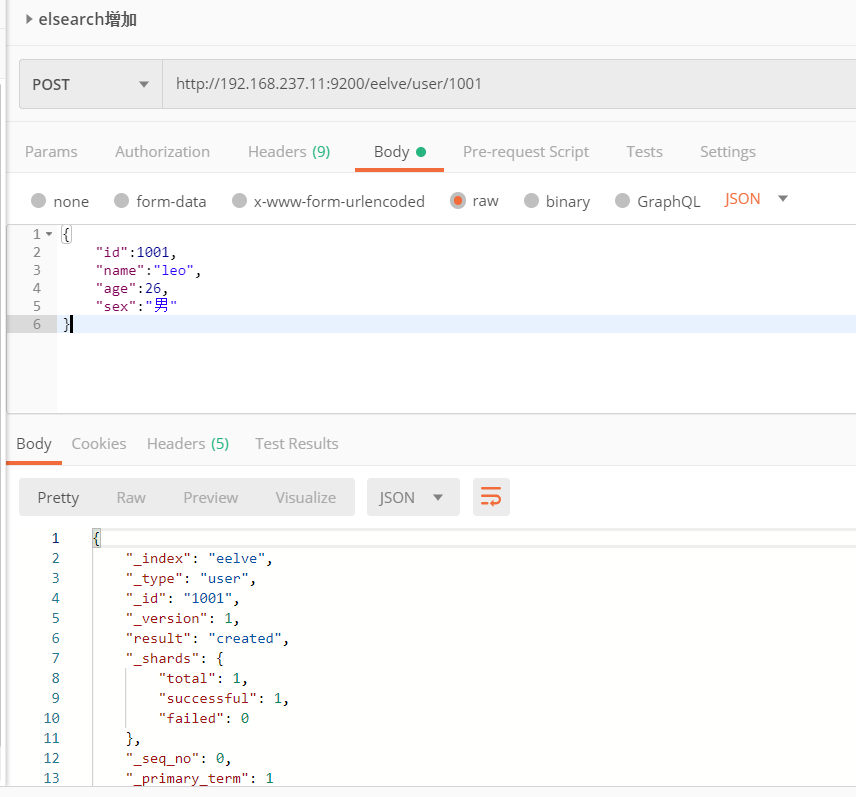
1、带id
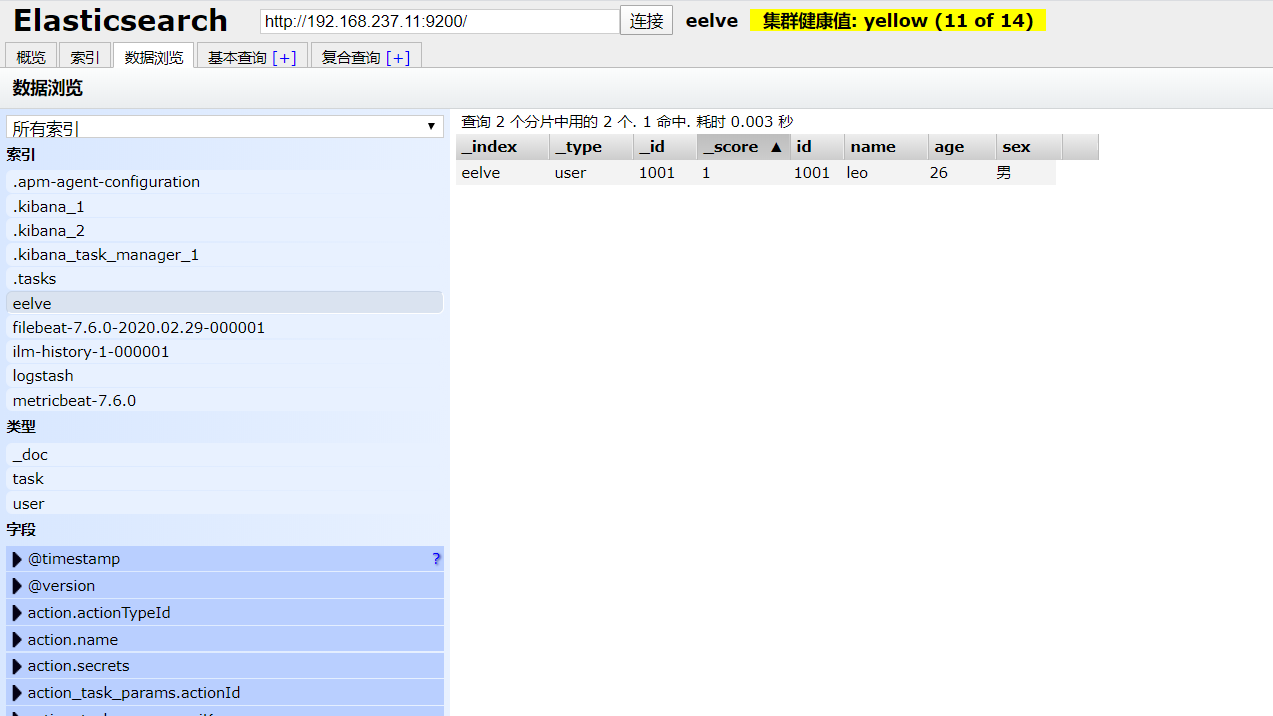
1 | POST /eelve/user/1001 |
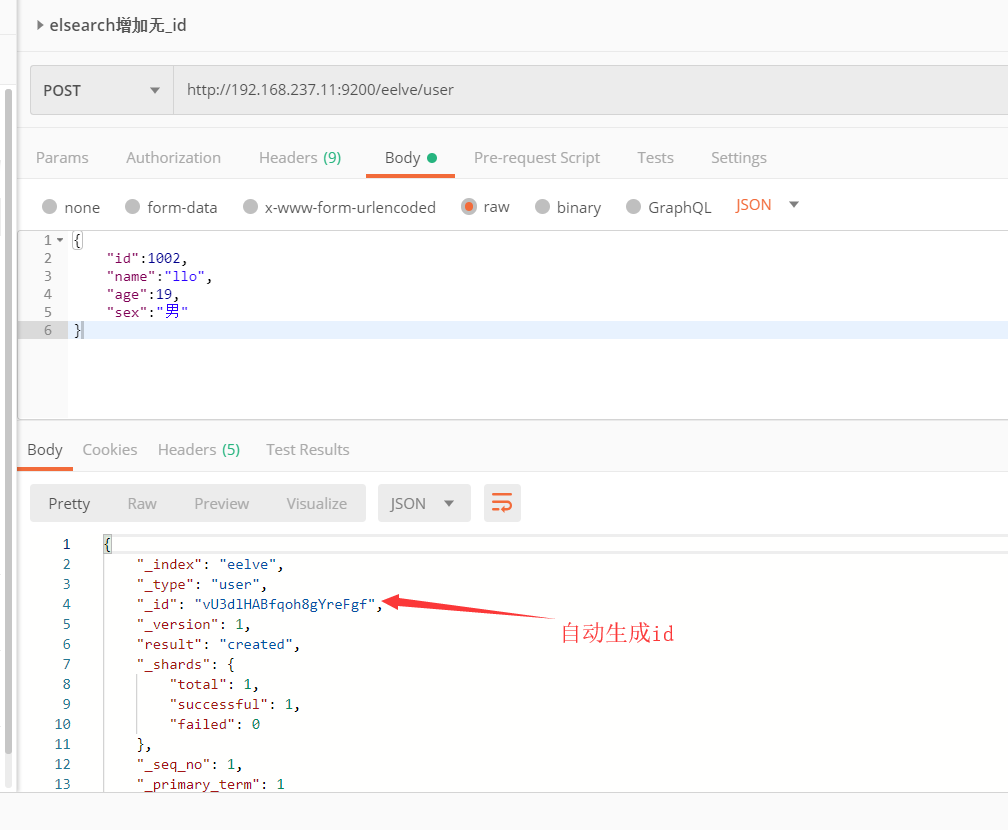
2、不带id
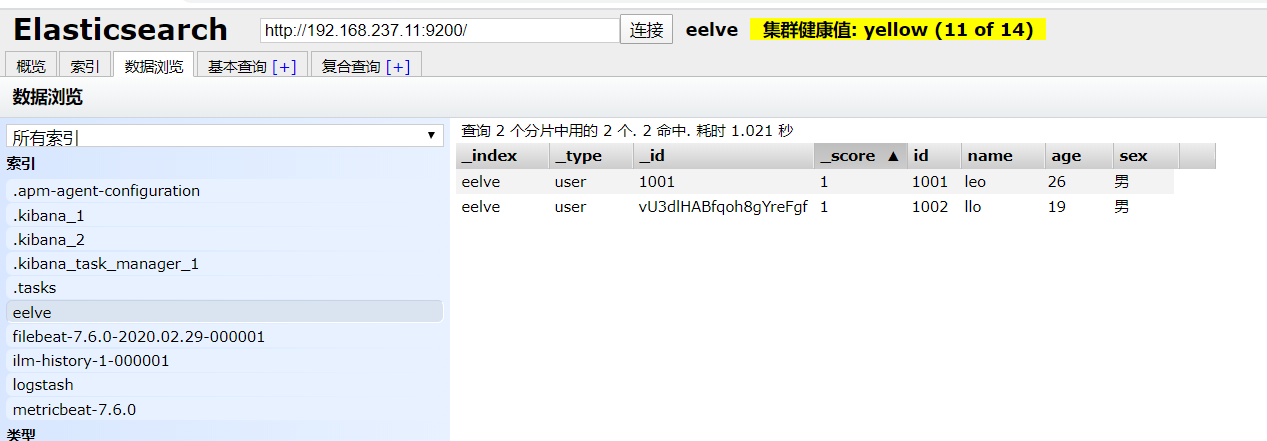
3.2.3 更新数据
在Elasticsearch中,文档数据是不为修改的,但是可以通过覆盖的方式进行更新。
1、全部修改
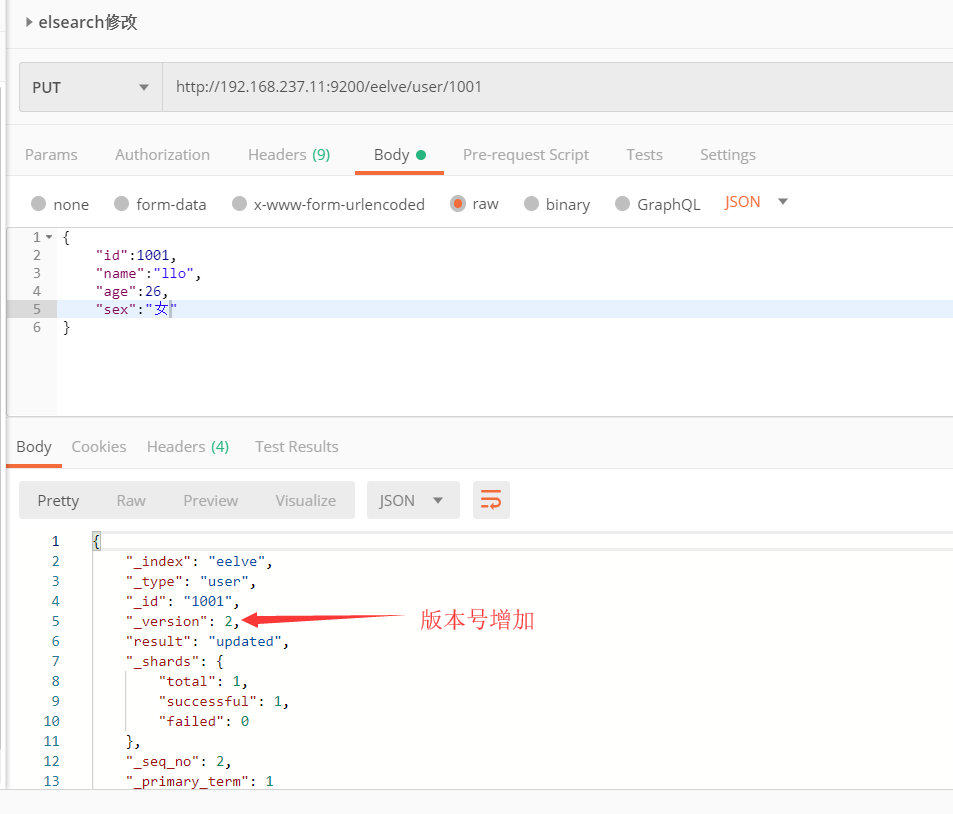
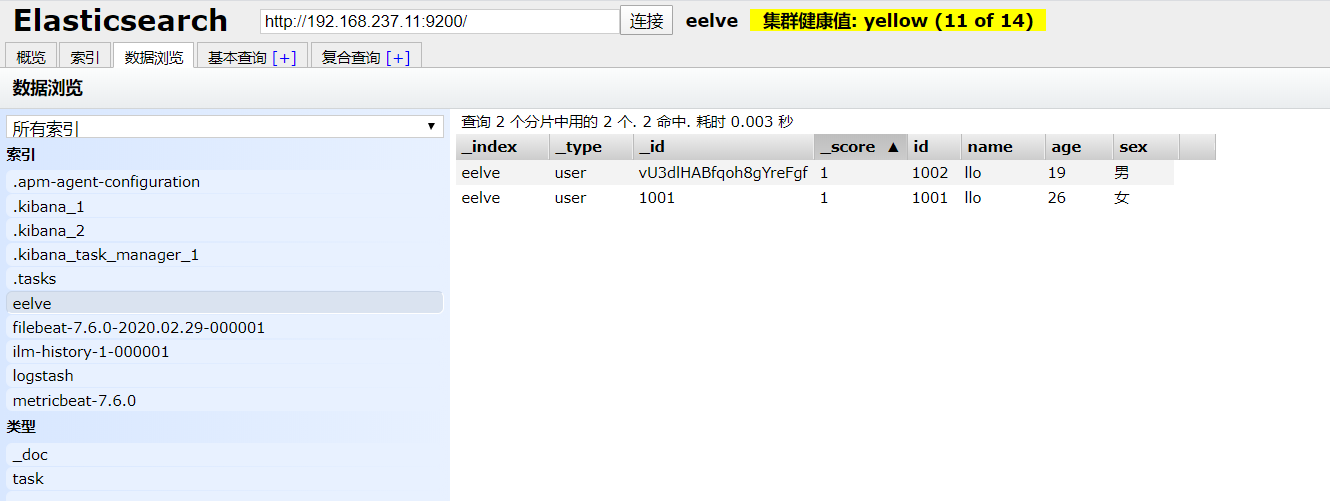
2、部分修改
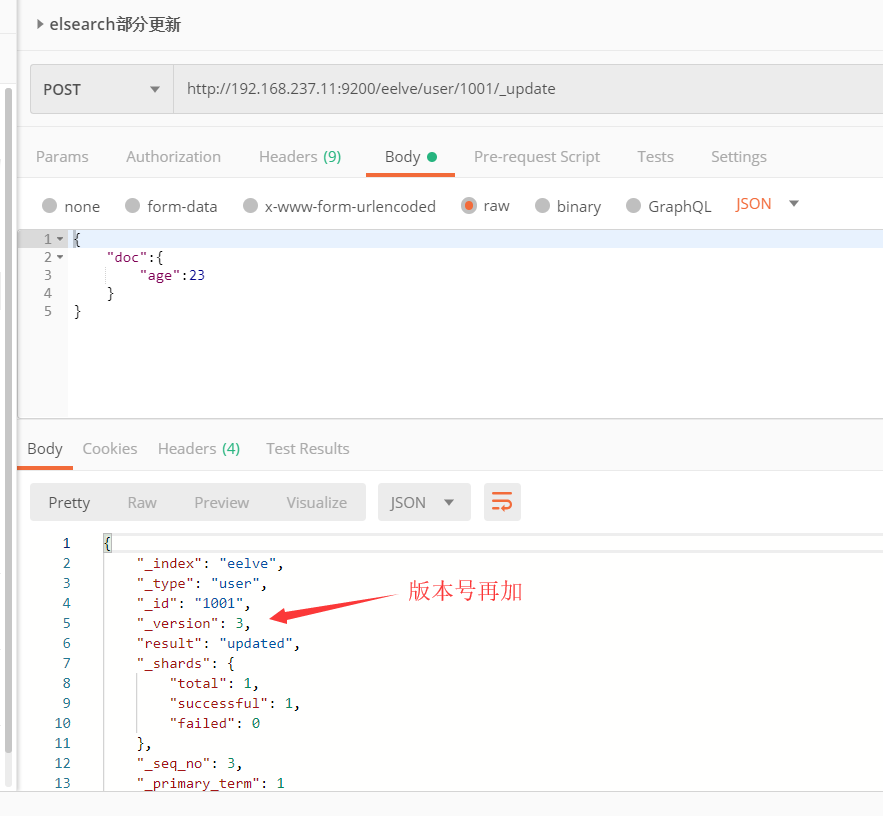
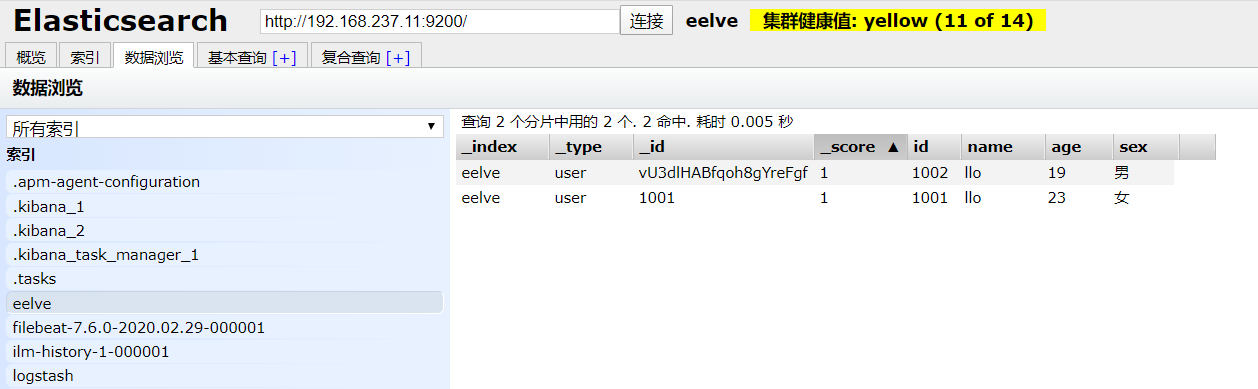
可以看到局部更新成功
3.2.4 删除数据
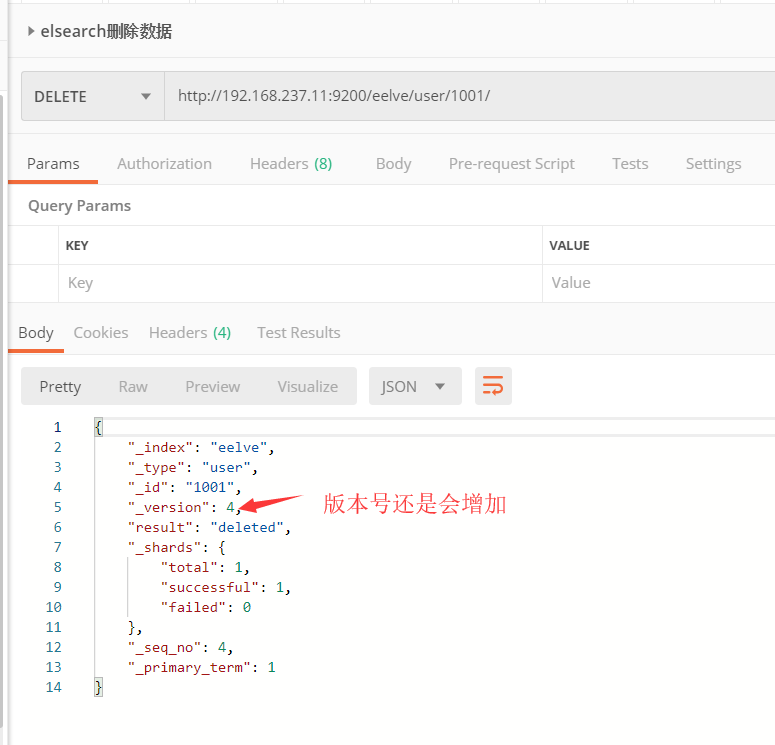
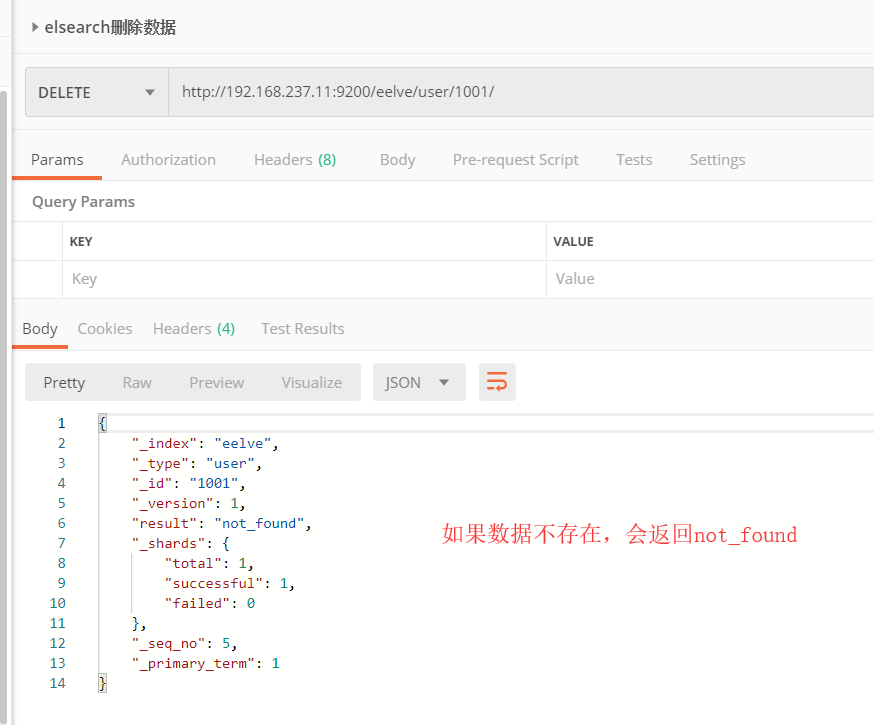
数据删除成功之后不会马上删除,只是会打上那个删除标识,Elasticsearch将会在你之后添加更多索引的时候才会在后台进行删除内容的清理。
3.2.5 搜索数据
1、根据id搜索
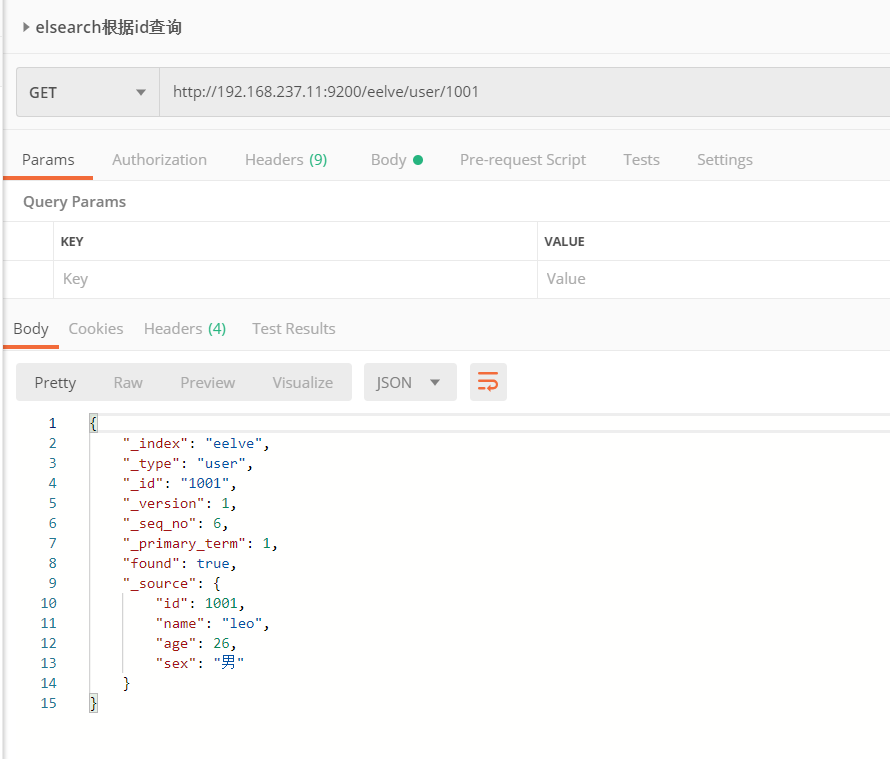
2、全部搜索
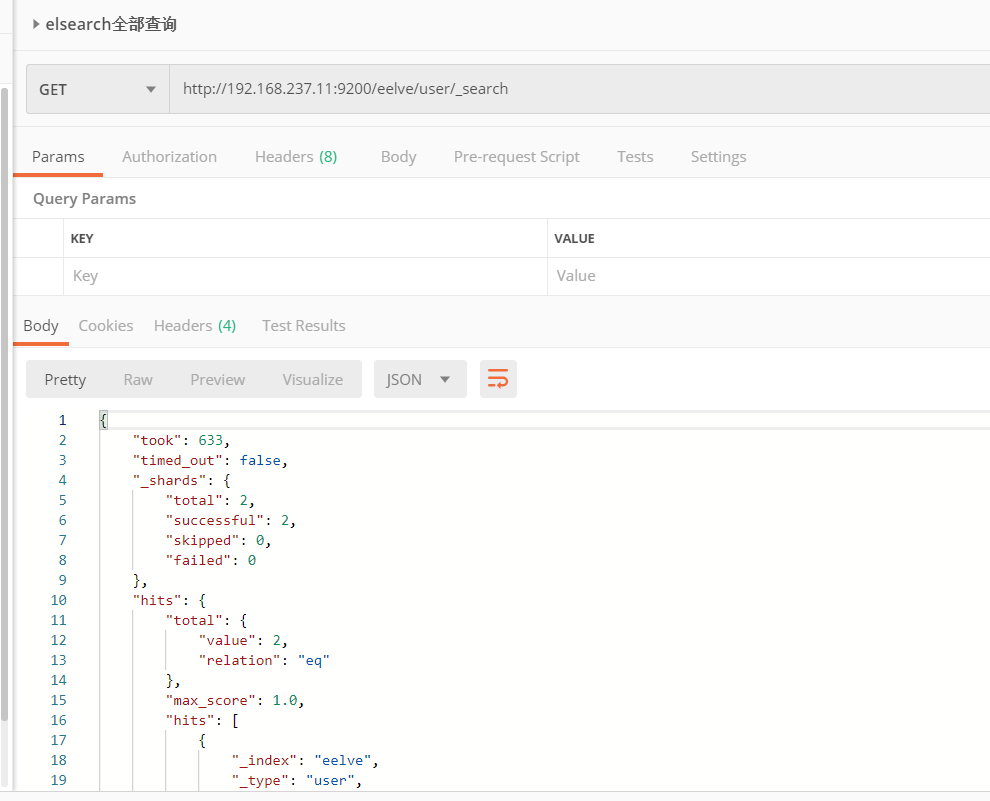
3、关键词搜索
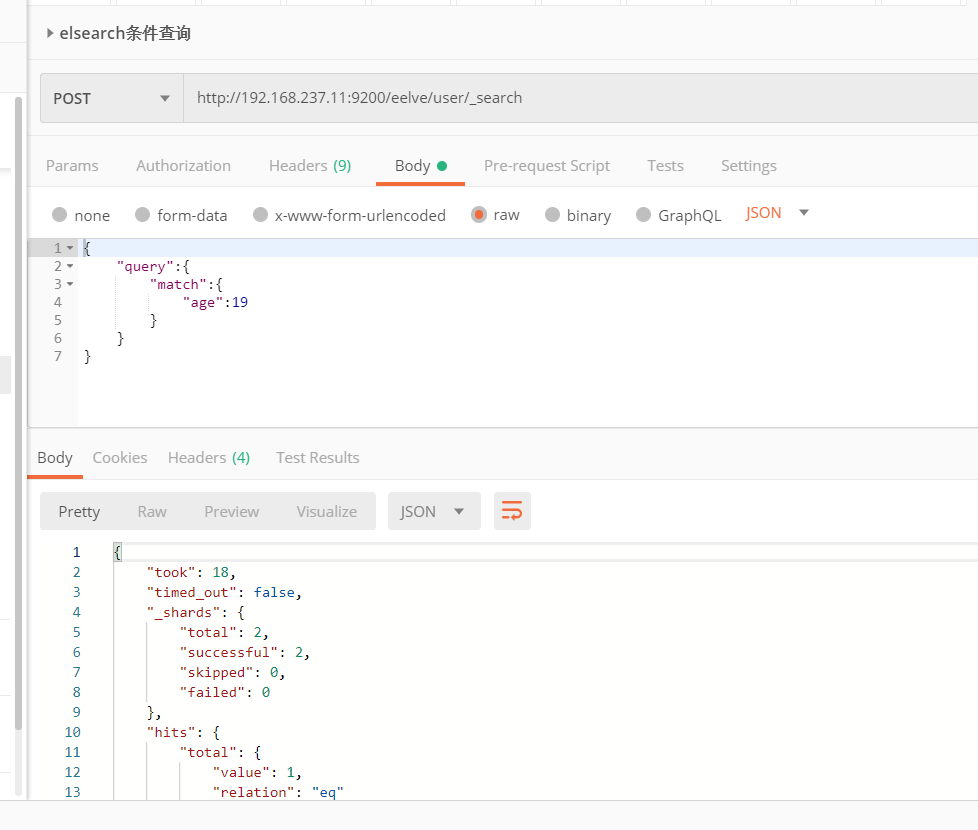
4、查询部分字段
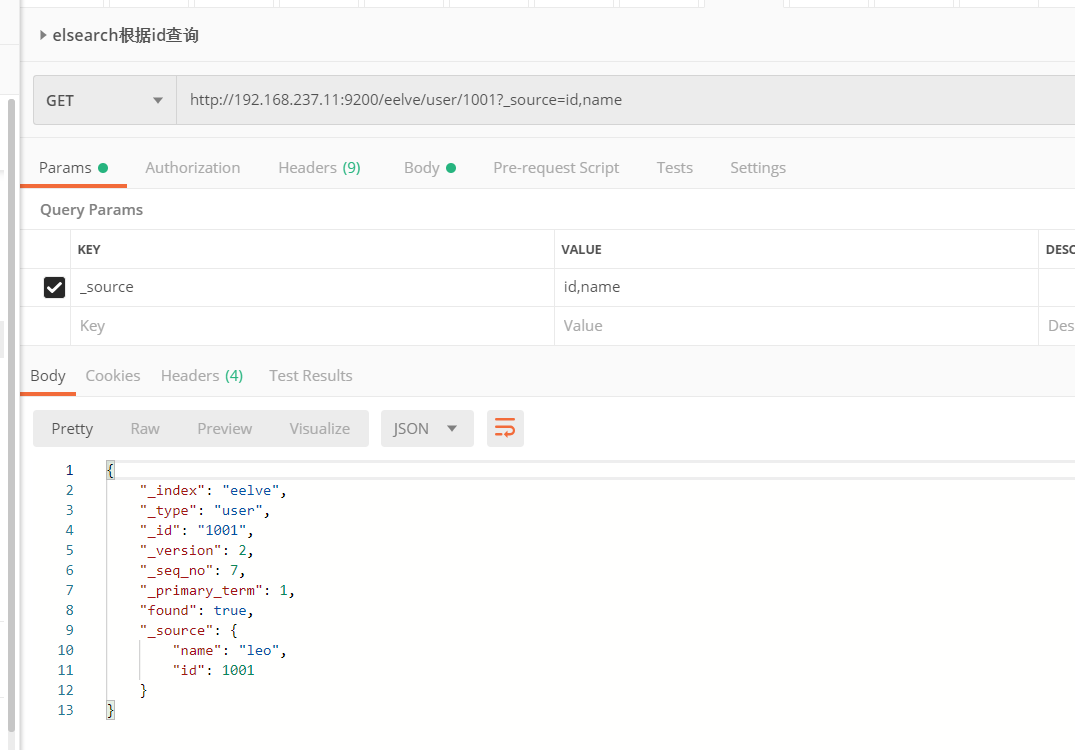
5、分页查询
和SQL使用 LIMIT 关键字返回只有一页的结果一样,Elasticsearch接受 from 和 size 参数:
size: 结果数,默认10
from: 跳过开始的结果数,默认0
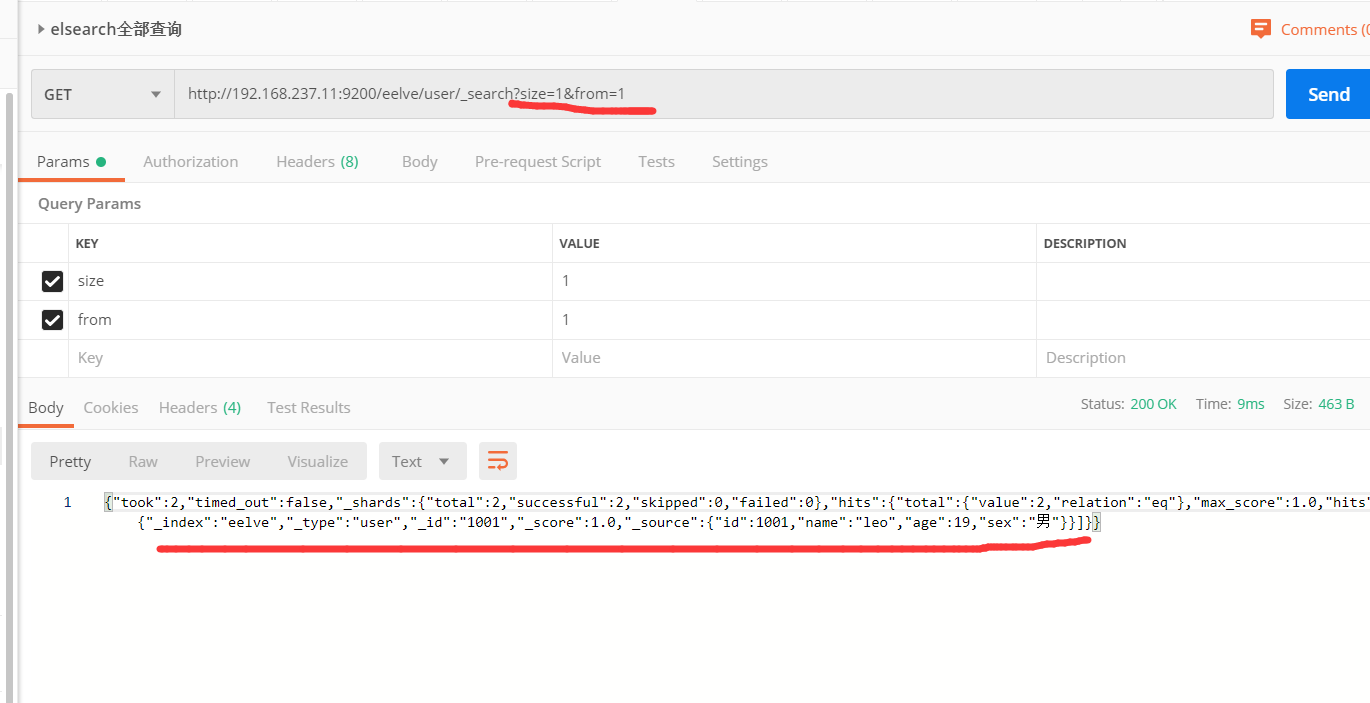
应该当心分页太深或者一次请求太多的结果。结果在返回前会被排序。但是记住一个搜索请求常常涉及多个分片。每个分片生成自己排好序的结果,它们接着需要集中起来排序以确保整体排序正确。
在集群系统中深度分页
为了理解为什么深度分页是有问题的,让我们假设在一个有5个主分片的索引中搜索。当我们请求结果的第一页(结果1到10)时,每个分片产生自己最顶端10个结果然后返回它们给请求节点(requesting node),
它再排序这所有的50个结果以选出顶端的10个结果。现在假设我们请求第1000页——结果10001到10010。工作方式都相同,不同的是每个分片都必须产生顶端的10010个结果。
然后请求节点排序这50050个结果并丢弃50040个!可以看到在分布式系统中,排序结果的花费随着分页的深入而成倍增长。这也是为什么网络搜索引擎中任何语句不能返回多于1000个结果的原因。
3.2.6 DSL搜索
Elasticsearch提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。
DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现
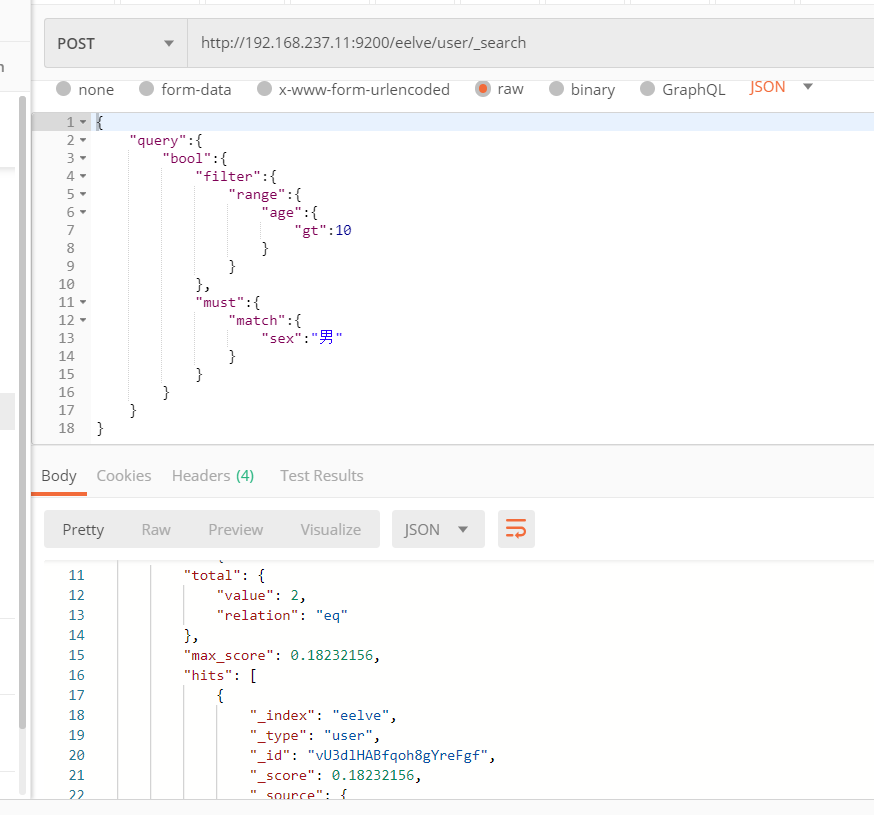
如图我们查询了一个年龄大于10岁,性别为男性的数据
3.2.7 聚合
在Elasticsearch中,支持聚合操作,类似SQL中的group by操作。
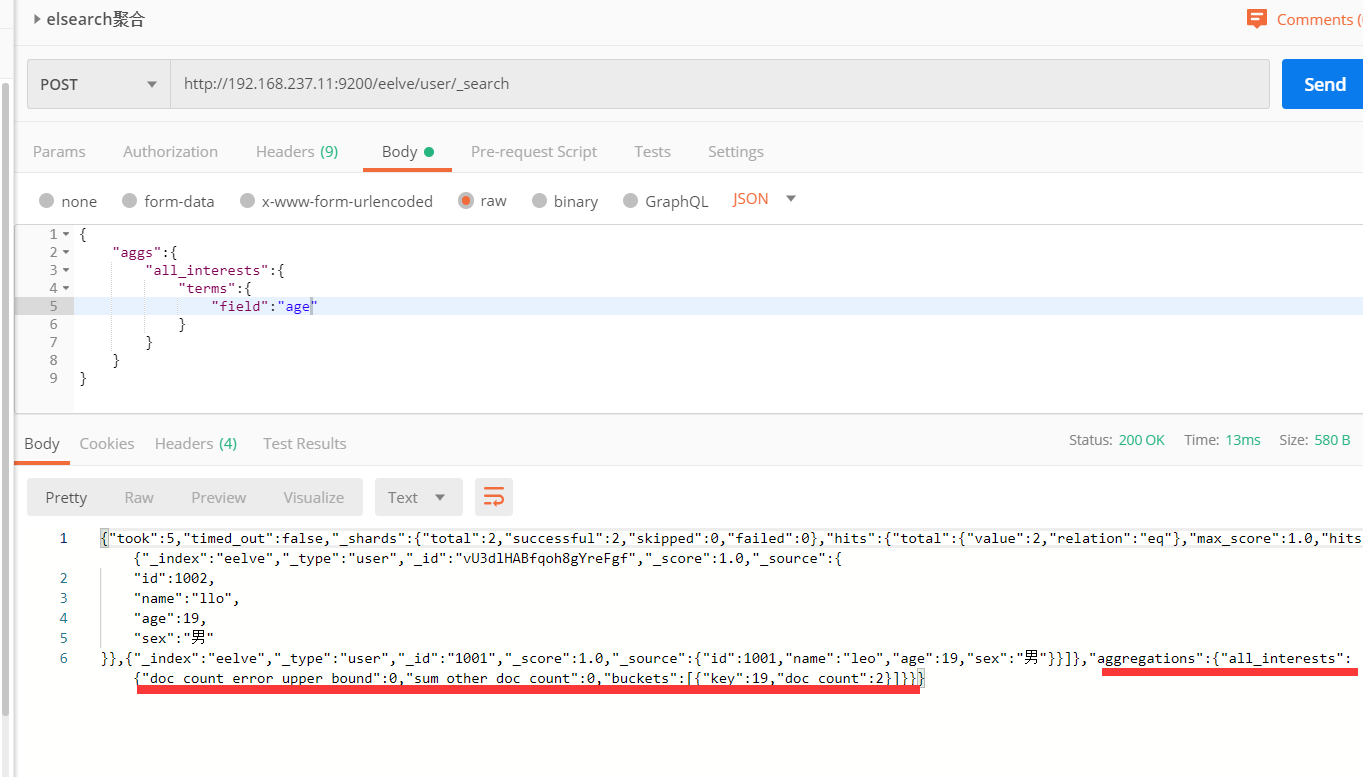
3.2.8 _bulk操作
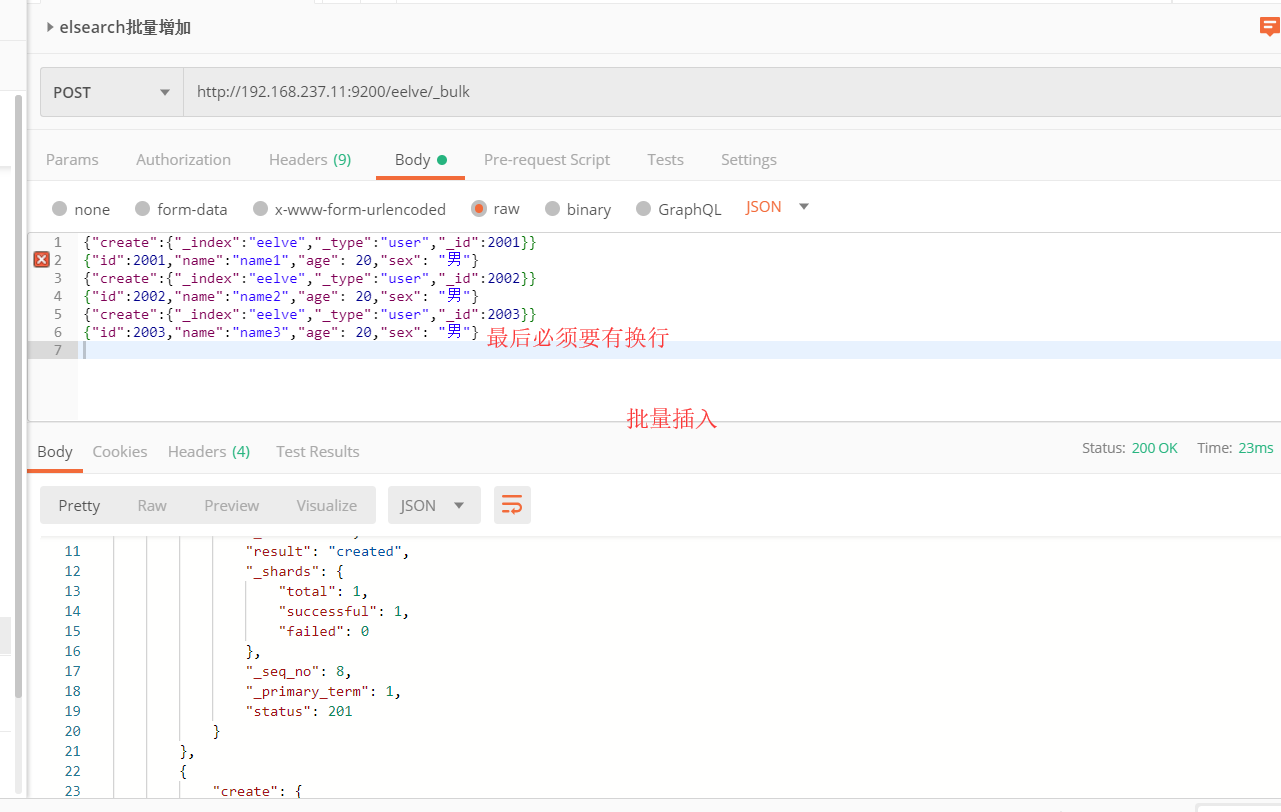
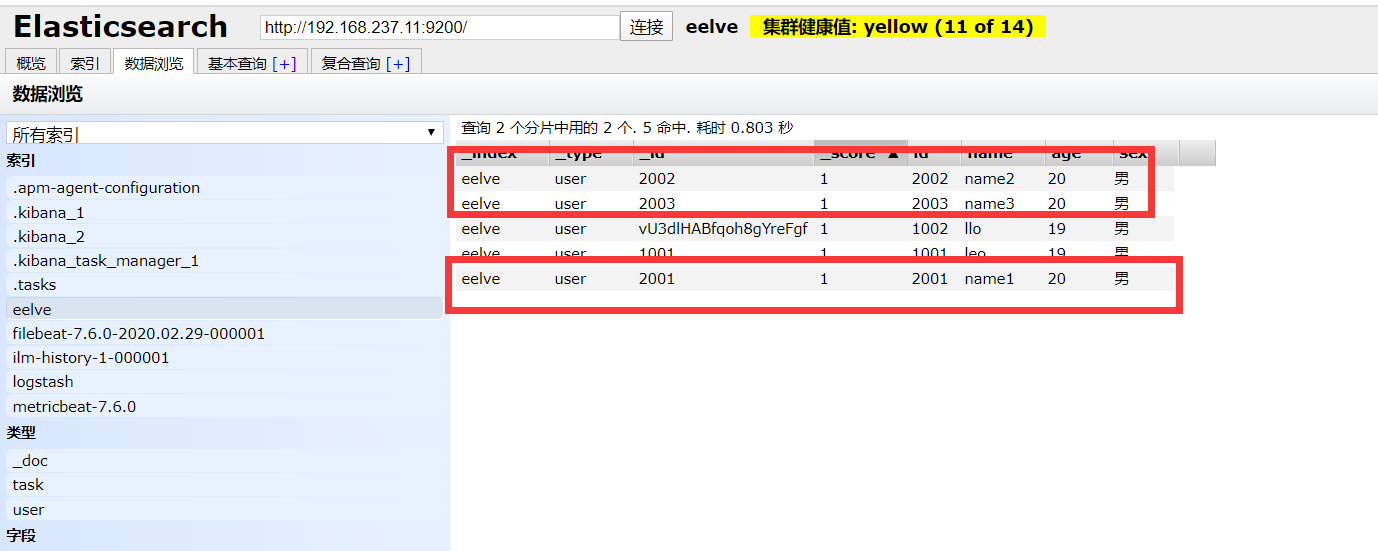
在Elasticsearch中,支持批量的插入、修改、删除操作,都是通过_bulk的api完成的。
1 | { action: { metadata }}\n |
1、批量插入
2、批量删除
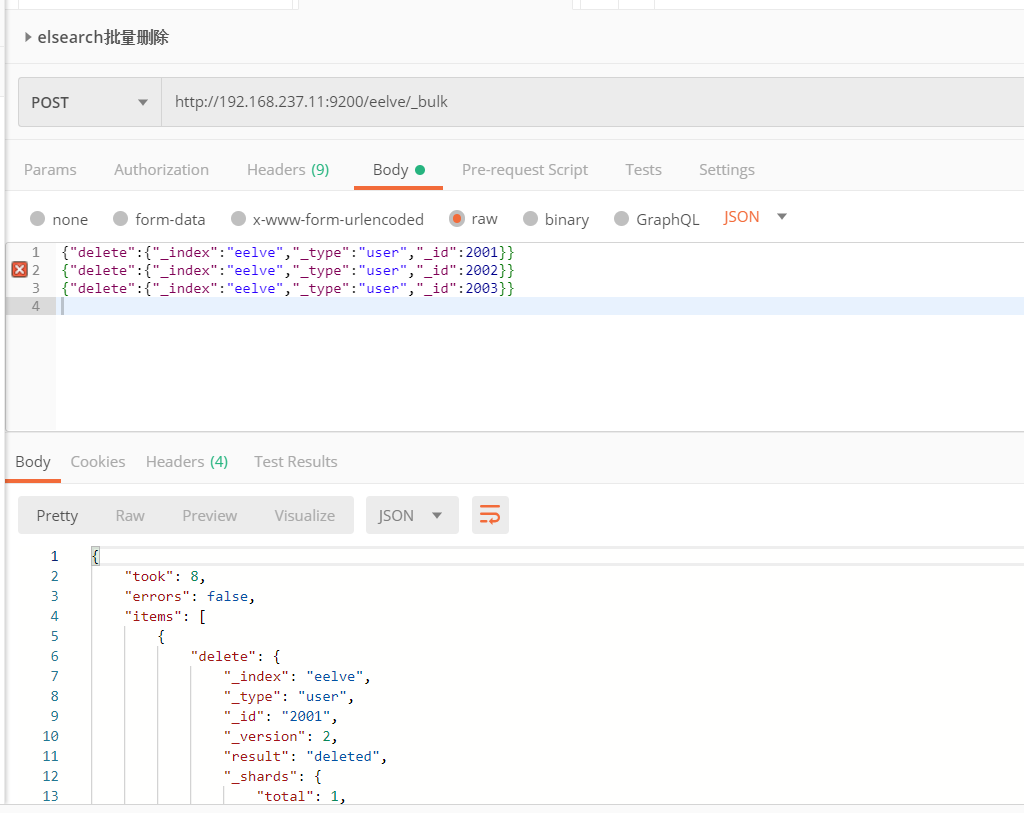
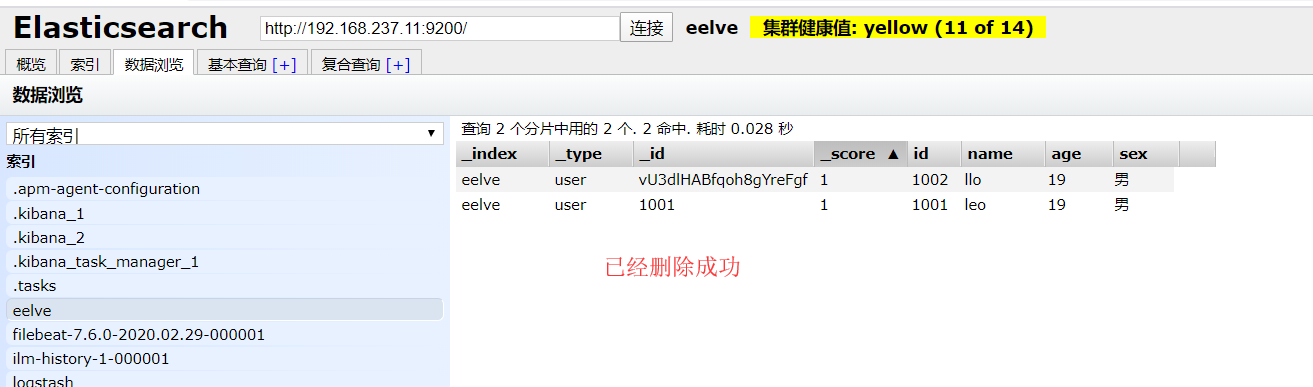
3、批量删除
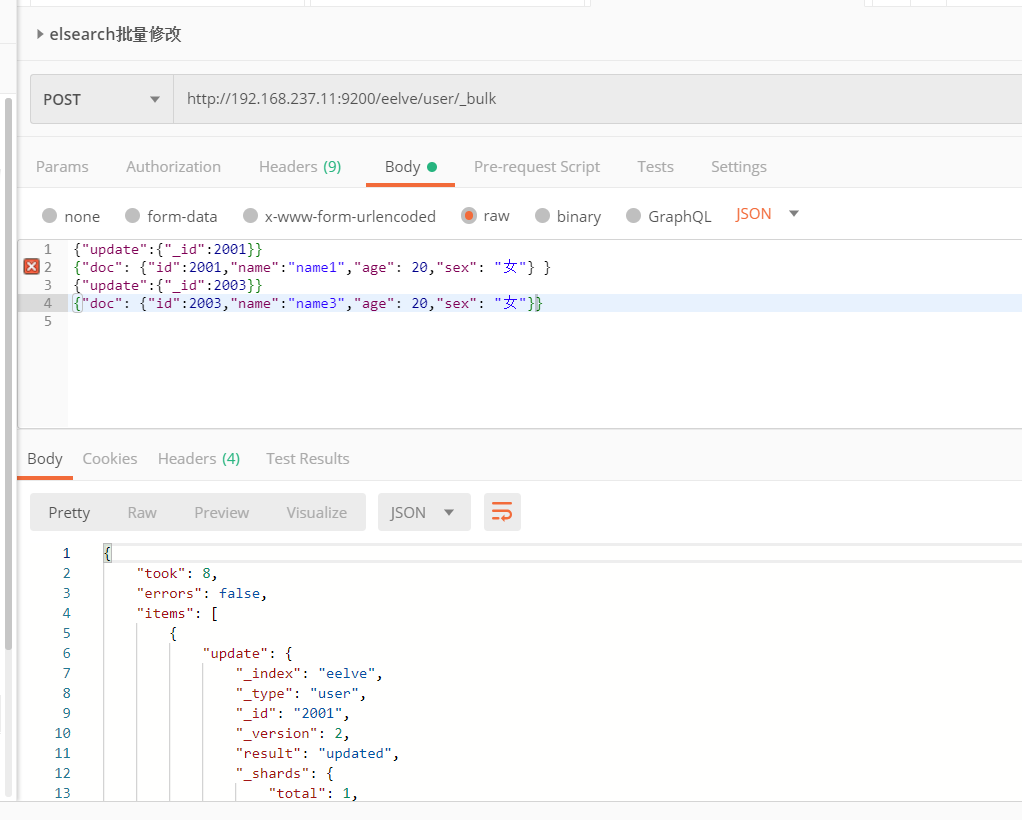
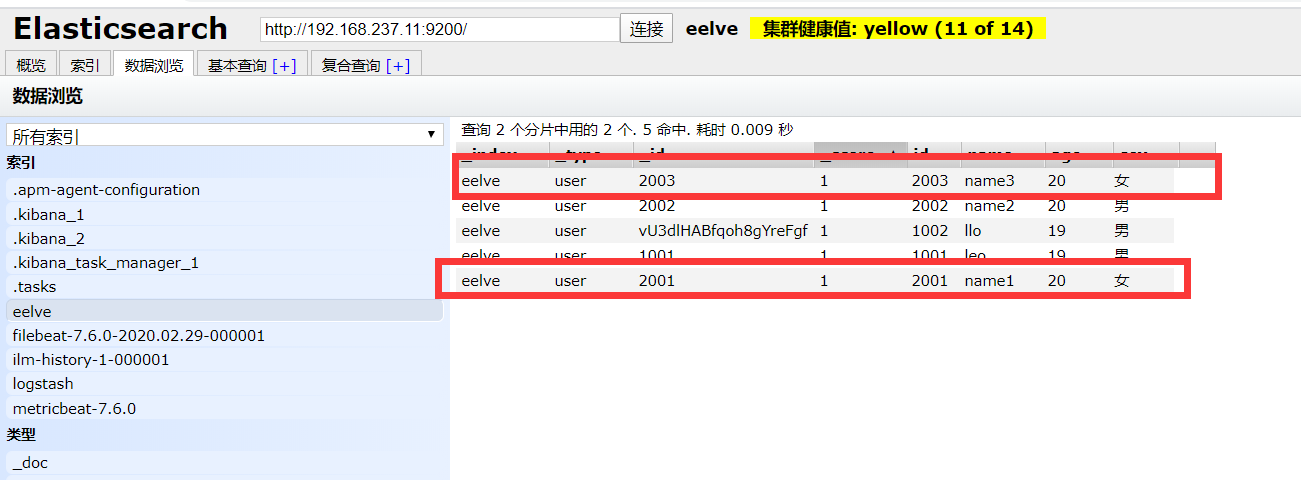
4、混合操作
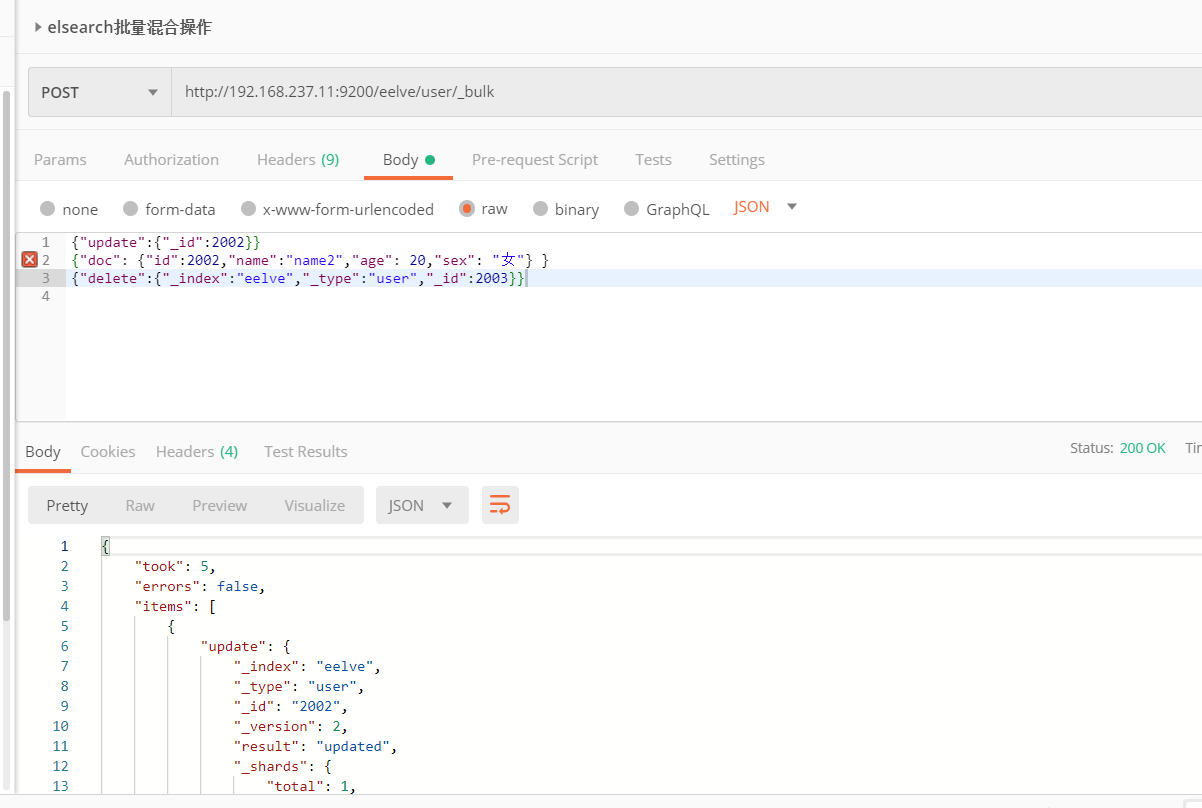
1 | { |
整个批量请求需要被加载到接受我们请求节点的内存里,所以请求越大,给其它请求可用的内存就越小。有一个最佳的bulk请求大小。
超过这个大小,性能不再提升而且可能降低。
最佳大小,当然并不是一个固定的数字。它完全取决于你的硬件、你文档的大小和复杂度以及索引和搜索的负载。
幸运的是,这个最佳点(sweetspot)还是容易找到的:试着批量索引标准的文档,随着大小的增长,当性能开始降低,
说明你每个批次的大小太大了。开始的数量可以在1000~5000个文档之间,如果你的文档非常大,可以使用较小的批次。
通常着眼于你请求批次的物理大小是非常有用的。一千个1kB的文档和一千个1MB的文档大不相同。一个好的批次最好保持在5-15MB大小间。
3.2.9 字段映射
前面我们创建的索引以及插入数据,都是由Elasticsearch进行自动判断类型,有些时候我们是需要进行明确字段类型的,否则,自动判断的类型和实际需求是不相符的。
自动判断的规则如下:
| SON type | Field type |
|---|---|
| Boolean: | true or false “boolean” |
| Whole number: | 123 “long” |
| Floating point: | 123.45 “double” |
| String, valid date: | “2014-09-15” “date” |
| String: | “foo bar” “string” |
Elasticsearch中支持的类型如下:
| 类型 | 表示的数据类型 |
|---|---|
| String | string , text , keyword |
| Whole number: | byte , short , integer , long |
| Floating point: | float , double |
| Boolean | boolean |
| Date | date |
string类型在ElasticSearch 旧版本中使用较多,从ElasticSearch 5.x开始不再支持string,由text和keyword类型替代。
text 类型,当一个字段是要被全文搜索的,比如Email内容、产品描述,应该使用text类型。设置text类型以后,字段内容会被分析,
在生成倒排索引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。
keyword类型适用于索引结构化的字段,比如email地址、主机名、状态码和标签。如果字段需要进行过滤(比如查找已发布博客中status属性为published的文章)、排序、聚合。
keyword类型的字段只能通过精确值搜索到。
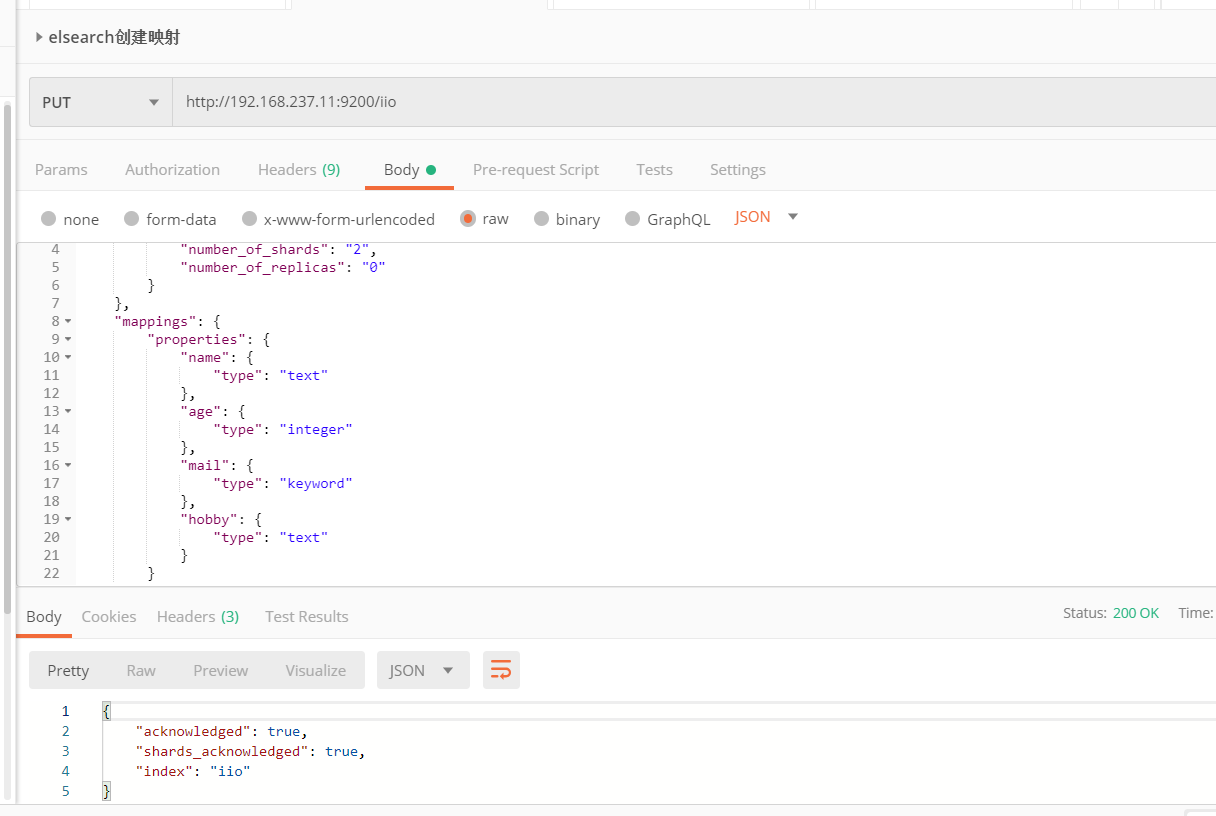
1 | { |
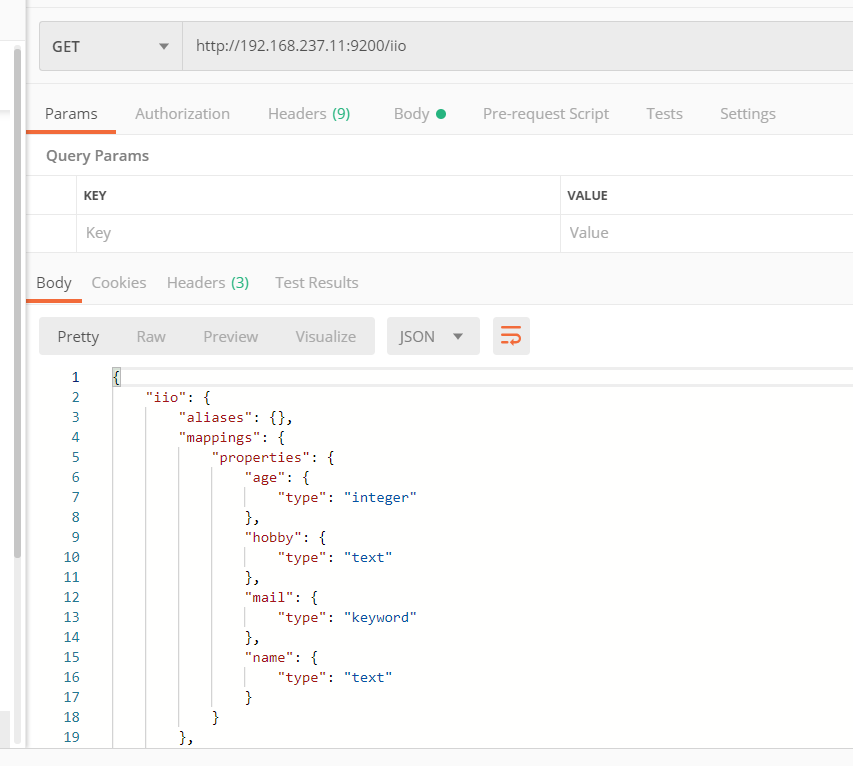
1 | { |
注意的是7.x的版本我6.x的版本创建索引不一样,6.x还需要在properties外面用类型包裹,下面给一个示例
1 | { |
肆、注意事项
注意版本差异,具体关注官方。我这边所演示的整个Elastic stack家族的版本都为7.6.0。另外批量操作的时候,如果有其中某一条执行失败的话,并不会影响其他执行正确的结果。
【后面的话】记住Elasticsearch是整个Elastic Stack的核心。具有查询分析、高速度、可扩展性、相关度和弹性,后面我们还会具体实践。另外关于Elasticsearch的还有组合搜索,权重,分词等等还没有实践,等后面实践之后文章会继续更新,可能会写一篇关于Elasticsearch深度使用的文章。
