【前面的话】前文介绍了Elastic Stack的Beats家族,今天我们就来体验其中的专门用于采集文件的Filebeat,走起。
壹、软件版本
1 | Centos:CentOS-7-x86_64-Minimal-1908 |
贰、Filebeat介绍
Filebeat是一种轻量型日志采集器,具有以下特点
- 汇总、“tail -f”和搜索:启动 Filebeat 后,打开 Logs UI,直接在 Kibana 中观看对您的文件进行 tail 操作的过程。通过搜索栏按照服务、应用程序、主机、数据中心或者其他条件进行筛选,以跟踪您的全部汇总日志中的异常行为。
性能稳健,不错过任何检测信号:无论在任何环境中,随时都潜伏着应用程序中断的风险。Filebeat 能够读取并转发日志行,如果出现中断,还会在一切恢复正常后,从中断前停止的位置继续开始。
Filebeat 让简单的事情简单化:Filebeat 内置有多种模块(Apache、Cisco ASA、Microsoft Azure、NGINX、MySQL 等等),可针对常见格式的日志大大简化收集、解析和可视化过程,只需一条命令即可。之所以能实现这一点,是因为它将自动默认路径(因操作系统而异)与 Elasticsearch 采集节点管道的定义和 Kibana 仪表板组合在一起。不仅如此,数个 Filebeat 模块还包括预配置的 Machine Learning 任务。
- 系统
- NGINX
- MySQL
- Auditd
容器就绪和云端就绪:正在对所有内容进行容器化,或者正在云端环境中运行?通过 Elastic Stack,可以轻松地监测容器和云服务。在 Kubernetes、Docker 或云端部署中部署 Filebeat,即可获得所有的日志流:信息十分完整,包括日志流的 pod、容器、节点、VM、主机以及自动关联时用到的其他元数据。此外,Beats Autodiscover 功能可检测到新容器,并使用恰当的 Filebeat 模块对这些容器进行自适应监测。
它不会导致您的管道过载:当将数据发送到 Logstash 或 Elasticsearch 时,Filebeat 使用背压敏感协议,以应对更多的数据量。如果 Logstash 正在忙于处理数据,则会告诉 Filebeat 减慢读取速度。一旦拥堵得到解决,Filebeat 就会恢复到原来的步伐并继续传输数据。

输送至 Elasticsearch 或 Logstash。在 Kibana 中实现可视化。
Filebeat 是 Elastic Stack 的一部分,因此能够与 Logstash、Elasticsearch 和 Kibana 无缝协作。无论您要使用 Logstash 转换或充实日志和文件,还是在 Elasticsearch 中随意处理一些数据分析,亦或在 Kibana 中构建和分享仪表板,Filebeat 都能轻松地将您的数据发送至最关键的地方。
叁 Filebeat安装
3.1 下载地址
3.2 解压filebeat-7.6.0-linux-x86_64
1 | tar -zvxf filebeat-7.6.0-linux-x86_64.tar.gz -C /usr/elastic |
3.3 filebeat配置
我们可以针对不同的采集项自定义配置,同时方便测试和展示。
3.4 采集控制台日志
- 新建std.yml配置
1 | filebeat.inputs: |
- 启动
1 | ./filebeat -e -c std.yml |
- 结果
1 | hello |
3.5 采集nginx日志
启动nginx
这里如果没有安装的话,可以自行安装配置,然后启动nginx
新建nginx.yml配置
1 | filebeat.inputs: |
- 启动Elasticsearch
1 | [iio@192 bin]$ ./elasticsearch |
- 启动Filebeat
1 | [iio@192 filebeat]$ ./filebeat -e -c nginx.yml |
- 刷新页面观察结果
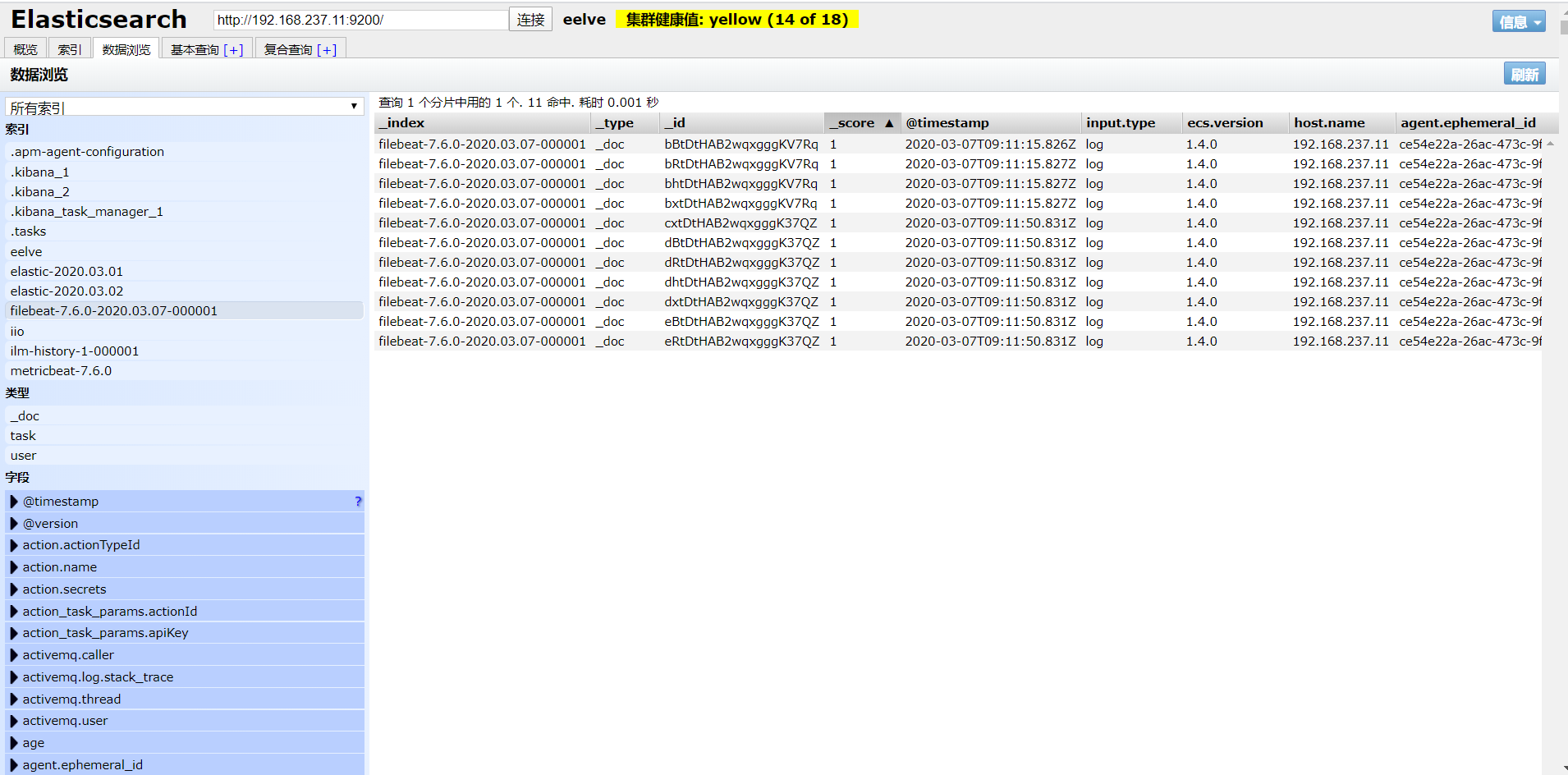
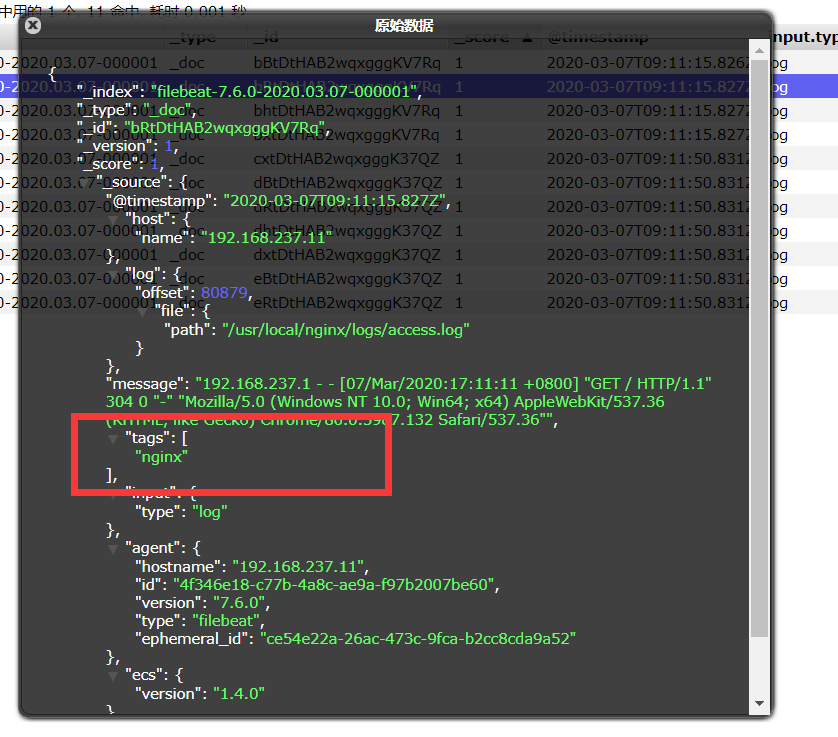
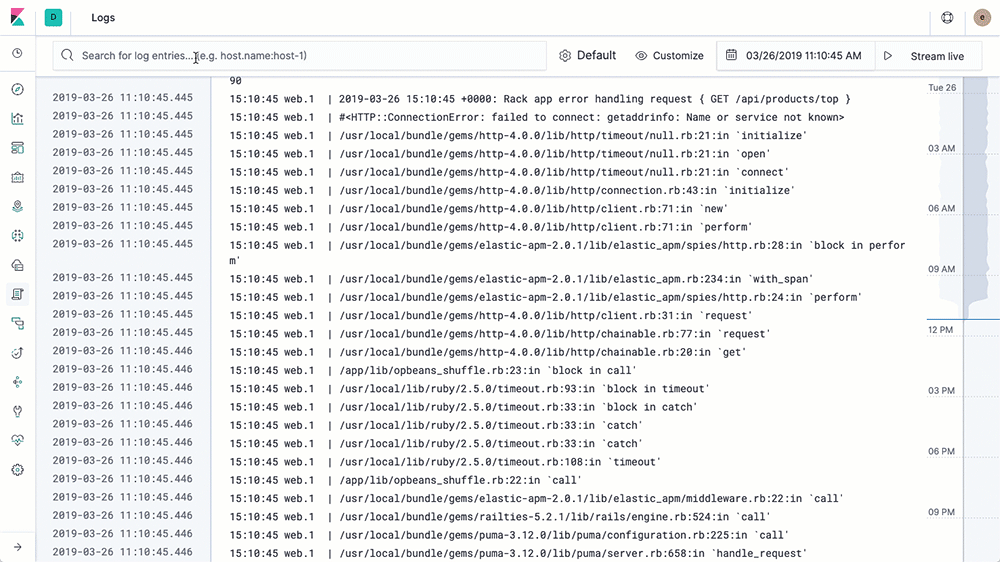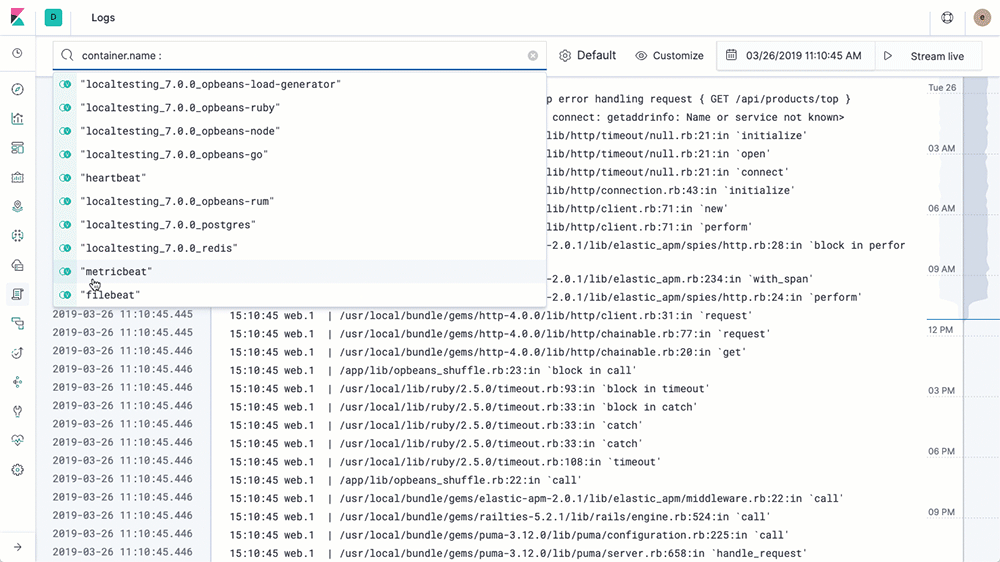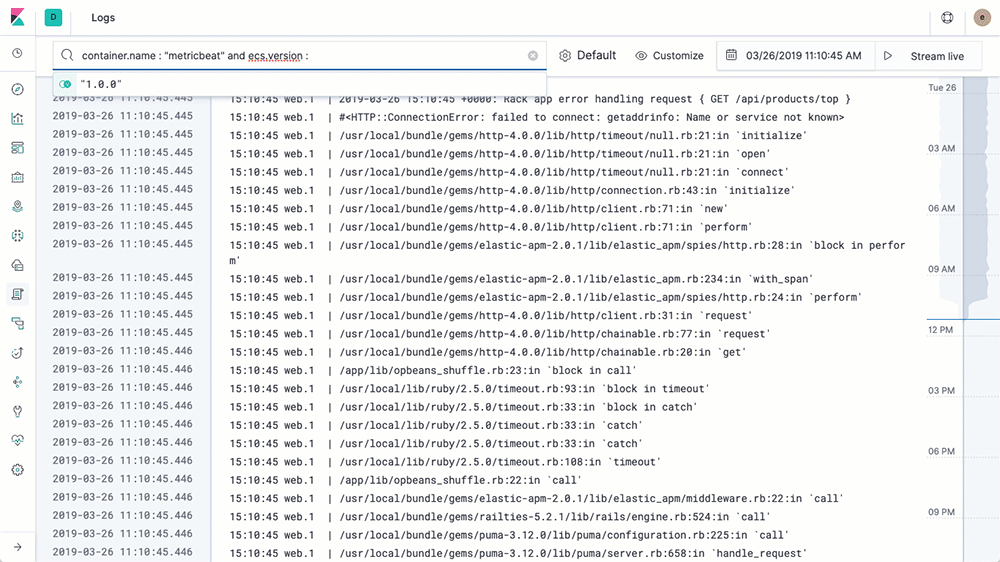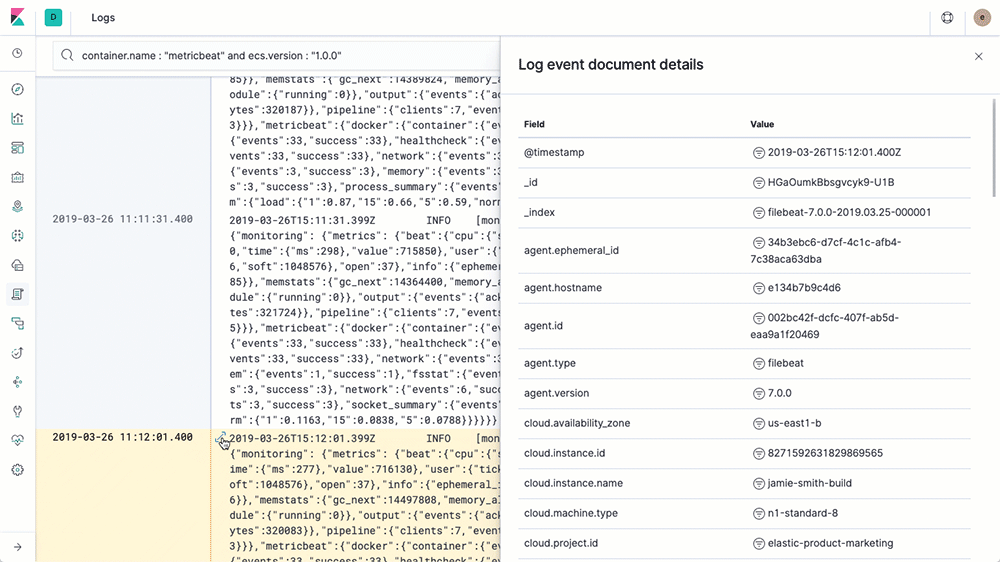
我们可以看到采集已经成功,并且我们配置的tags也已经成功了
3.6 使用nginx module采集nginx日志
- 开启filebeat的nginx module
前面要想实现日志数据的读取以及处理都是自己手动配置的,其实,在Filebeat中,有大量的Module,可以简化我们的配置,直接就可以使用,如下:
1 | [iio@192 filebeat]$ ./filebeat modules list |
可以看到我这里的nginx modules已经开启了,但是默认是没有开启的,如果需要启用需要进行enable操作:
1 | /filebeat modules enable nginx #启动 |
- nginx module 配置
1 | [iio@192 filebeat]$ cd modules.d |
- 配置filebeat
1 | [iio@192 filebeat]$ vi nginxmodule.yml |
- 启动
1 | [iio@192 filebeat]$ ./filebeat -e -c nginxmodule.yml |
- 查看结果
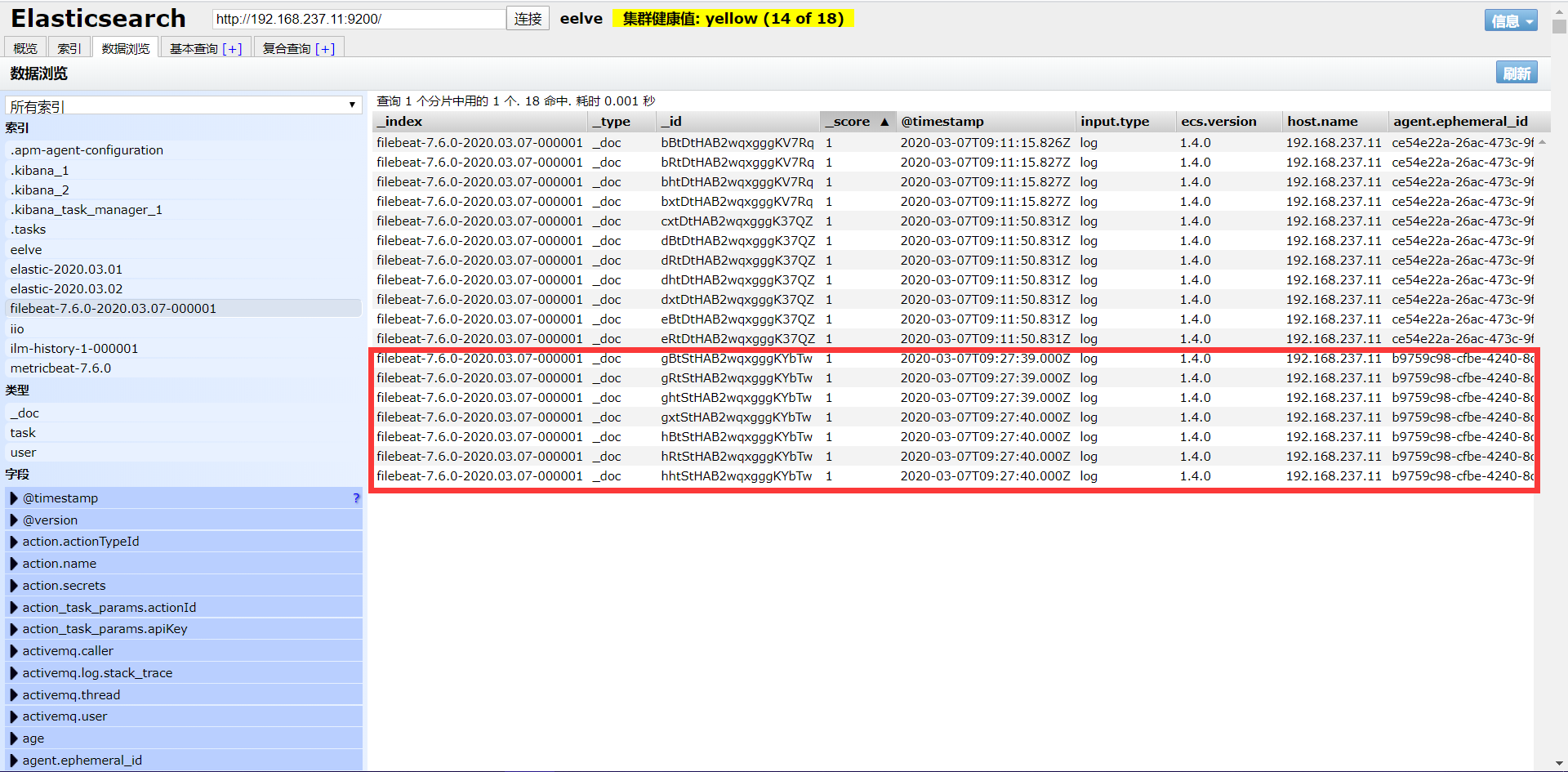
1 | { |
我们开用使用filebeat提供的modules采集nginx日志也成功,而且可以看到展示的信息也更加完善了。可以看到filebeat提供的各种modules就是帮我们做了一些解析工作,其他modules的用法类似。
3.7 使用Kibana展示
- 修改filebeat配置
1 | [iio@192 filebeat]$ vi iio.yml |
- 启动Kibana
下面的安装仪表板依赖Kibana,也就是Kibana必须启动才能安装仪表盘
- 安装仪表盘
1 | #安装仪表盘到Kibana |
- 启动Filebeat
1 | ./filebeat -e -c iio.yml |
- 观察结果
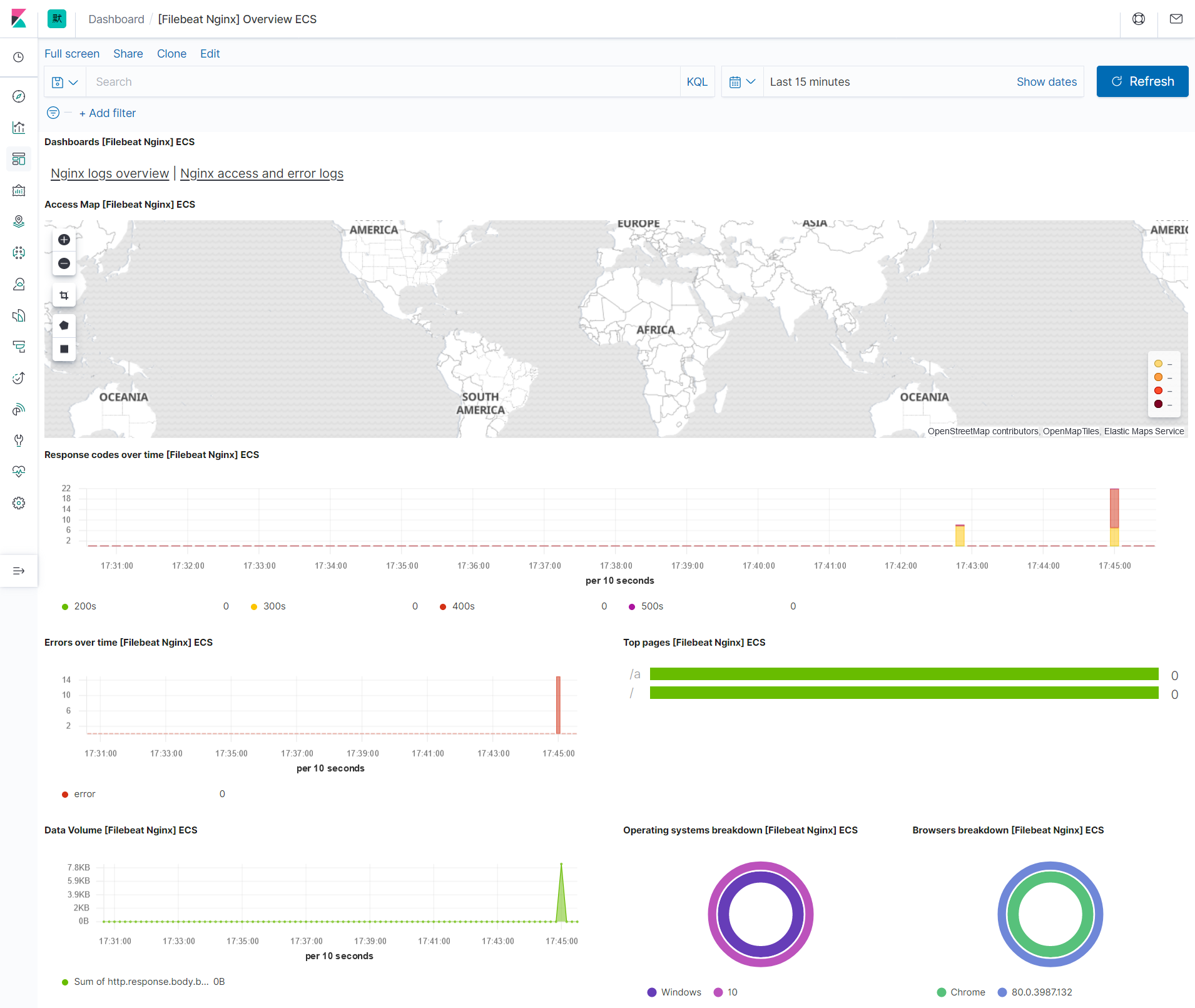
可以看到Kibana内置的nginx的仪表盘的展示情况,展示相当仿佛,并且还可以随着时间变化而刷新
肆、Filebeat工作原理
Filebeat由两个主要组件组成:prospector 和 harvester。
harvester:
- 负责读取单个文件的内容。
- 如果文件在读取时被删除或重命名,Filebeat将继续读取文件。
prospector:
- prospector 负责管理harvester并找到所有要读取的文件来源。
- 如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个harvester。
- Filebeat目前支持两种prospector类型:log和stdin。
Filebeat如何保持文件的状态
- Filebeat 保存每个文件的状态并经常将状态刷新到磁盘上的注册文件中。
- 该状态用于记住harvester正在读取的最后偏移量,并确保发送所有日志行。
- 如果输出(例如Elasticsearch或Logstash)无法访问,Filebeat会跟踪最后发送的行,并在输出再次可用时继续读取文件。
- 在Filebeat运行时,每个prospector内存中也会保存的文件状态信息,当重新启动Filebeat时,将使用注册
- 文件的数据来重建文件状态,Filebeat将每个harvester在从保存的最后偏移量继续读取。
- 文件状态记录在data/registry文件中。
```shell script
启动命令
./filebeat -e -c itcast.yml
./filebeat -e -c itcast.yml -d “publish”
#参数说明e: 输出到标准输出,默认输出到syslog和logs下
c: 指定配置文件
d: 输出debug信息
#测试: ./filebeat -e -c iio.yml -d “publish”
---
【**后面的话**】在本文中我们全面的体验了一下filebeat,还和Kibana结合应用了,我们可以看到filebeat和elk三大剑客整合的非常好,特别是Kibana提供了丰富的仪表盘,大大的方便了我们展示。后面还有再结合一下Logstash,使用以下过滤功能。
---
